Ollama Cloud 的 Pro 套餐有一个周配额上限,但官方没说这个配额到底对应多少 token。前端只显示"当前已使用百分之几"和消耗的 token 数。
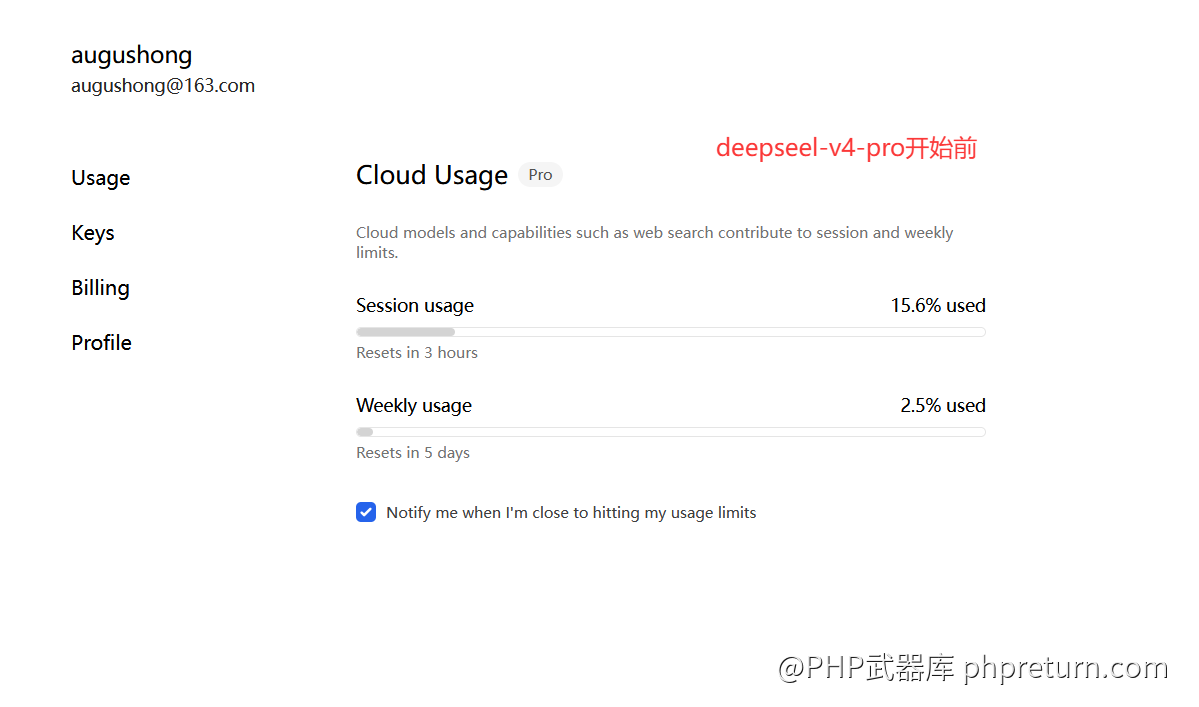
我的办法很直接:逐个模型跑一轮,记下消耗量和百分比,反推总配额。为了准确监控每次调用的 token 消耗和延迟数据,我专门部署了一套 New API 作为中间代理,所有请求都经过它转发,这样每次调用的输入输出 token、首字时间、总耗时都有完整记录。
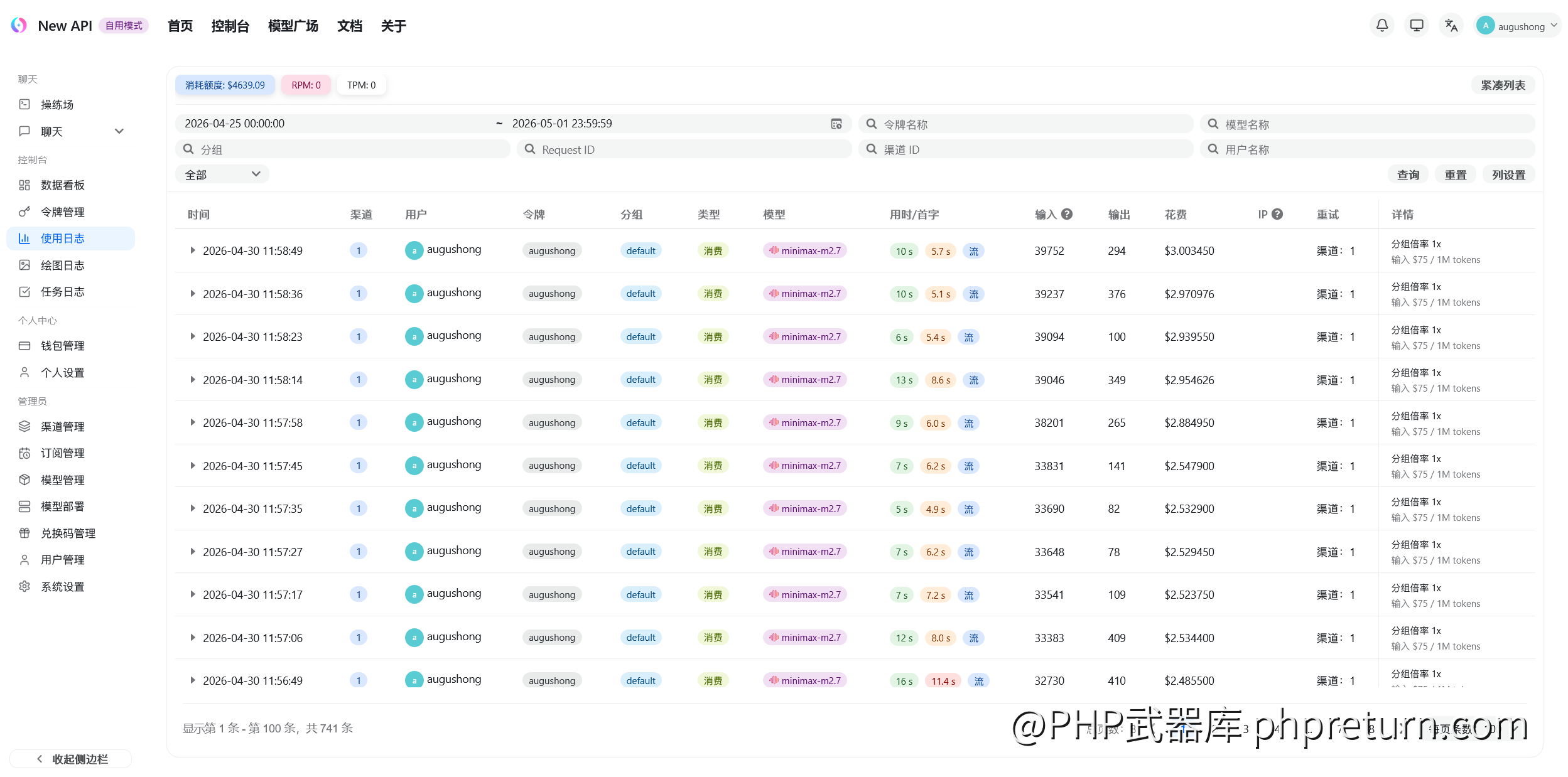
反推公式:周总配额 = 消耗 token 数 / 占用百分比。百分比有 ±0.1% 的显示误差,所以每个数据给了一个范围值。
实验数据
批次 1 -- GLM-5.1 消耗 200 万 token,占用 0.5%配额。反推月总 13.33 亿 ~ 16.00 亿 ~ 20.00 亿 token。
批次 2 -- DeepSeek-V4-Pro 消耗 1240 万 token,占用 0.6%配额。反推月总 70.86 亿 ~ 82.67 亿 ~ 99.20 亿 token。
批次 3 -- DeepSeek-V4-Pro(二次验证) 消耗 3140 万 token,占用 1.6%配额。反推月总 73.88 亿 ~ 78.50 亿 ~ 83.73 亿 token。
批次 4 -- kimi-k2.6 消耗 570 万 token,占用 1.1%配额。反推月总 19.00 亿 ~ 20.73 亿 ~ 22.80 亿 token。
批次 5 -- deepseek-v4-flash 消耗 2785 万 token,占用 1.1%配额。反推月总 92.84 亿 ~ 101.28 亿 ~ 111.40 亿 token。
批次 6 -- minimax-2.7 消耗 2738 万 token,占用 2.7%配额。反推月总 39.12 亿 ~ 40.56 亿 ~ 42.13 亿 token。
每组三个数字分别是 -0.1% / 直接 / +0.1% 的反推结果,考虑了百分比显示的精度误差。月总按周 x4 估算。
情况总结
按月估算(周 x4),如果只用单一模型,各模型的月配额大概是:
| 模型 | 月配额(亿 token) |
|---|---|
| deepseek-v4-flash | 101.28 |
| DeepSeek-V4-Pro | 82.67 |
| minimax-2.7 | 40.56 |
| kimi-k2.6 | 20.73 |
| GLM-5.1 | 16.00 |
不同模型之间差异很大——flash 系列月产 100 亿 token,GLM-5.1 只有 16 亿,差了 6 倍。如果配额是纯 token 计数,不管用什么模型结果应该一样。
这说明配额实际上是按 GPU 时间算的,不是按 token 数。推理快的模型(flash 系列)单位 GPU 时间产出更多 token,所以反推出来的"总配额"更大。慢模型(GLM-5.1、minimax-2.7)单 token 占用更多 GPU 时间,配额消耗得更快。
minimax-2.7 的数据最能说明问题:消耗了 2738 万 token 占 2.7%,deepseek-v4-flash 消耗了 2785 万 token 只占 1.1%。差不多相同的 token 数量,minimax-2.7 吃掉的配额是 flash 的 2.45 倍。实际体验也印证了这一点——minimax-2.7 首字延迟接近 5 秒,flash 几乎即时。
简单说:选什么模型直接决定你的配额能跑多少 token。 想最大化产出,优先用 flash 模型;需要强推理再用 Pro 模型,但要做好配额消耗更快的心理准备。
和智谱 Pro 的对比
智谱的 Pro 套餐同样用 GLM-5.1,经推算每月大概能用 30 亿 token,比 Ollama Cloud 上跑 GLM-5.1 的 16 亿多了将近一倍。如果主要用 GLM 系列,智谱的套餐明显更划算。
但智谱有个高峰期三倍消耗的机制。如果只在高峰期用,30 亿直接缩水到 10 亿左右,反而不如 Ollama Cloud 了。所以到底哪个划算,取决于你的使用时间分布——非高峰期用智谱,全时段用 Ollama Cloud。
和 DeepSeek 官方的对比
Ollama Cloud Pro 月费约 140 元。如果全跑 DeepSeek,V4-Flash 理论月产 101 亿 token,V4-Pro 理论月产 83 亿。那同样的 token 量,在 DeepSeek 官方按量付费要花多少钱?
DeepSeek V4 官方定价(促销期 2.5 折,截至 2026-05-31):
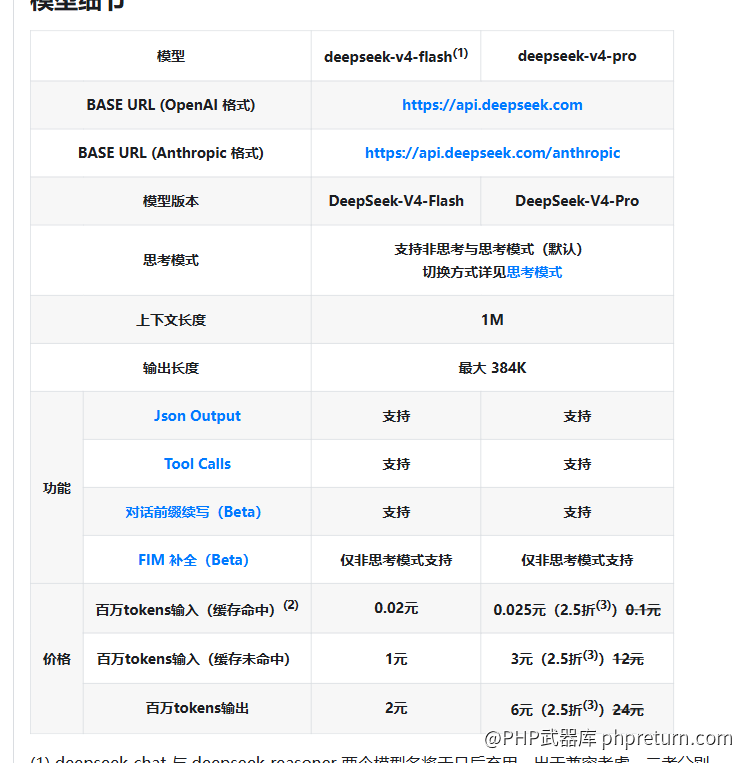
- V4-Flash:缓存命中 0.02 元/百万 token,缓存未命中 1 元/百万 token,输出 2 元/百万 token
- V4-Pro:缓存命中 0.025 元/百万 token,缓存未命中 3 元/百万 token,输出 6 元/百万 token
按输入输出 3:1 的典型用量(75% 输入、25% 输出),Ollama Cloud 产出的 token 量在 DeepSeek 官方需要花费:
缓存命中率取决于每次请求中重复前缀占总输入的比例。system prompt 长、对话轮次多,缓存命中就高;每次都是全新长文本输入,缓存命中就低。99% 是极端乐观情况,日常使用大多在 50%-80% 之间。
V4-Flash(Ollama Cloud 理论月产 101 亿 token)
99% 缓存命中:约 5273 元
V4-Pro 促销价(Ollama Cloud 理论月产 83 亿 token)
99% 缓存命中:约 12927 元
即使按缓存命中率 99% 的极端乐观情况算,DeepSeek 官方也要五千多(V4-Flash)到一万多(V4-Pro)。Ollama Cloud 只要约 140 元。即便打个对折,差距仍然是数量级的。
当然,DeepSeek 官方在稳定性和响应速度上远好于 Ollama Cloud 的转接。追求 token 产出量选 Ollama Cloud,追求稳定和速度选 DeepSeek 官方。
稳定性
这次测试中,GLM-5.1、kimi-k2.6、minimax-2.7 都会出现偶尔变慢的情况,但一般问题不大,等一下就恢复。整体稳定性不如官方接口,即便是晚上和早上这种低峰时段,首字时间也至少 2-3 秒。
DeepSeek 是另一个级别的不稳定。不光是慢的问题,经常出现超时、中断、响应质量波动大。做实际开发的时候,这种不稳定性比速度慢更影响效率。
如果你在用 Ollama Cloud 并且想知道某个特定模型的配额消耗情况,评论区留言,我可以继续测试更新数据。也欢迎分享你在其他平台(智谱、DeepSeek 官方、硅基流动等)的套餐 token 使用情况,放在一起对比才有参考价值。
原文标题: Ollama Cloud Pro 配额到底怎么算:6 个模型实测反推
原文地址: https://phpreturn.com/index/a69f49c0090371.html
原文平台: PHP武器库
版权声明: 本文由phpreturn.com(PHP武器库官网)原创和首发,所有权利归phpreturn(PHP武器库)所有,本站允许任何形式的转载/引用文章,但必须同时注明出处。