任务队列看着简单:往里塞,排队,拿出来执行。真上手才会撞上一堆细节。
worker 领走一个 job 跑到一半崩了,服务器怎么知道要把它重新派给别人?30 分钟后发提醒邮件,队列里怎么实现"延迟可见"?一批任务里 VIP 用户的要插队先跑,怎么标优先级?有个 job 反复失败,不想继续重试又不想直接删掉,放哪?
每一个单独看都不难,但攒到一起,就是"任务队列"该解决的全部问题。
Beanstalkd 是一个把这些都想清楚了的服务。它只做任务队列这一件事,但把 worker 崩溃回收、延迟、优先级、失败任务隔离全做成了原生能力,不用自己实现。
一个二进制,跑起来再说
Beanstalkd 是 C 写的,编译出来就一个二进制文件。没有依赖,没有配置文件,没有 Web 管理后台要装。
Docker 一行:
docker run -d -p 11300:11300 --name beanstalkd maateen/docker-beanstalkd
跑起来,监听 11300 端口,完事。协议是纯文本的,你可以直接 telnet 上去手敲命令调试,这点比 RabbitMQ 那套 AMQP 爽多了:
$ telnet 127.0.0.1 11300
stats
list-tubes
stats-tube default
peek-ready
quit
实际跑起来,投几个 job 进去,连上看真实输出:
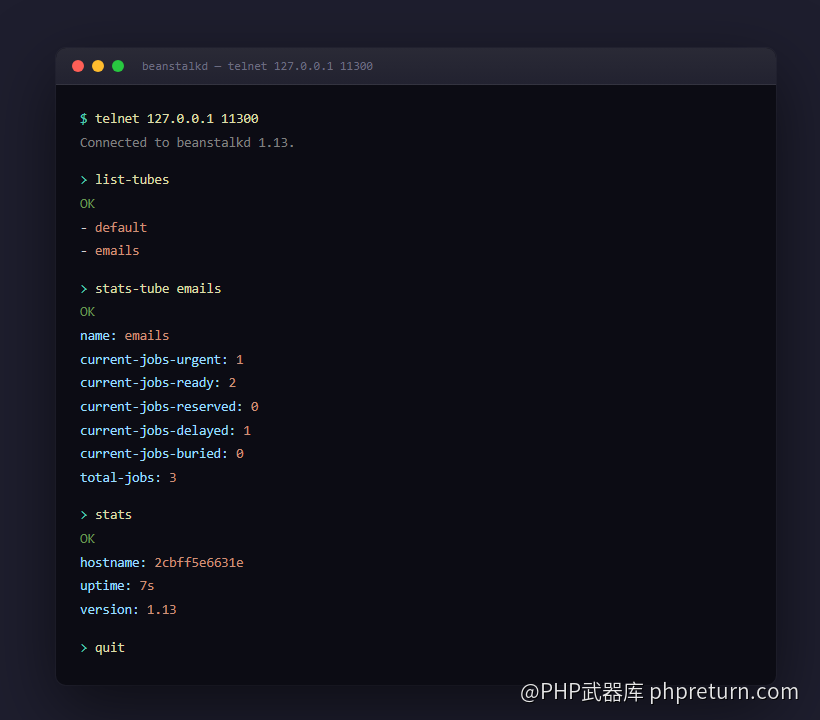
这种"能直接用 telnet 跟服务对话"的设计,排查问题的时候省太多事了。
四个状态,一套机制
Redis 做队列只有两个状态:在 List 里,或者不在。Beanstalkd 给每个 job 设计了四个状态,正好覆盖任务队列该有的所有场景:
put(delay>0) 到期自动
┌──────────────────► DELAYED ──────────┐
│ ▼
│ ┌─────────┐
│ put(delay=0) │ READY │
│ ┌─────────────────────►│ │
│ │ └────┬────┘
│ │ │ reserve
│ │ ▼
│ │ ┌──────────┐
│ │ release │ RESERVED │
│ │ ◄──────────────────│ │
│ │ └────┬─────┘
│ │ bury ┌───────┴──────┐ delete
│ │ ▼ ▼
│ │ ┌────────┐ ┌─────────┐
│ │ │ BURIED │ │ (消失) │
│ │ └────┬───┘ └─────────┘
│ │ kick │
│ └───────────────────┘
│ TTR 超时也会从 RESERVED 自动回 READY
- ready:就绪,等 worker 领
- reserved:被某 worker 领走,正在处理
- delayed:延迟中,到点才变 ready
- buried:被埋(人工搁置),不会自动重跑,只能 kick 唤醒
tube 就是"一个命名的队列"。生产者用 use 选 tube 投递,消费者用 watch 订阅 tube 领取。一个消费者能同时 watch 多个 tube,reserve 时从任意一个有活儿的 tube 取。
投递一个 job 时有三个核心参数:
-
priority(优先级):数字越小越优先,
0最紧急。默认1024——这个设计很巧,留出 0~1023 给"插队"用,日常任务用 1024 排在后面。 - delay(延迟):几秒后才变 ready。做定时任务、延迟队列直接用这个,不用 ZSET 轮询。
- TTR(time-to-run):worker 领走后允许跑多久。超时了服务器自动把 job 放回 ready 队列,让别人重试。
TTR 这套机制,是 Redis 给不了的
TTR 解决的就是开头提的第一个问题——worker 领走 job 后崩了怎么办。
在 Beanstalkd 里,worker reserve 拿到 job 的瞬间,服务器开始倒计时。worker 必须在 TTR 内做三件事之一:delete(处理完了)、release(处理不了,放回去)、bury(彻底坏掉,埋掉)。三件都没做?TTR 到了,服务器自动把这个 job 放回 ready 队列,别的 worker 会重新领到它。
job 不会丢,也不会因为 worker 崩溃而卡死。
还有个细节叫 DEADLINE_SOON:当某个 reserved job 快超时了(大约剩 1 秒),worker 再调 reserve 会收到这个警告,意思是"你手上那个快超时了,赶紧处理完或者 release"。频繁收到这个警告,说明你的 TTR 设得太短。
长任务怎么办?比如一个 job 要跑 5 分钟,但 TTR 默认只有 60 秒。答案是 touch——周期性调用它重置 TTR 计时器,等于给 job"续命":
$job = $pheanstalk->reserveWithTimeout(0);
while (stillWorking()) {
doChunkOfWork();
$pheanstalk->touch($job); // 重置 TTR,防止被服务器回收
}
$pheanstalk->delete($job);
bury/kick:失败任务的人工通道
worker 遇到不可重试的异常(比如数据格式就是错的),调 bury 把 job 埋掉。被埋的 job 不会自动重跑,停在 buried 状态等人工处理。排查完了,调 kick 把它(们)唤醒回 ready 队列。
这套机制在 Redis 里要自己实现,而且通常实现得很糙。Beanstalkd 原生给你了。
PHP 实战:pheanstalk
PHP 生态里 Beanstalkd 的主流客户端是 pheanstalk。包名 pda/pheanstalk,当前版本 v8.0.2(2025 年 11 月),要求 PHP 8.3+。
composer require pda/pheanstalk
踩坑提醒:网上 2023 年前的 pheanstalk 教程几乎全是 v4 写法,用了链式调用(->watch($tube)->reserve())和字符串 tube 名。这些在 v5+ 全部不能用了。照抄老教程会直接报错,别问我怎么知道的。
v5+ 的规矩:tube 名必须用 TubeName 值对象,方法调用不能链式,一个调用一行。
Producer(生产者)
<?php
require 'vendor/autoload.php';
use Pheanstalk\Pheanstalk;
use Pheanstalk\Values\TubeName;
$pheanstalk = Pheanstalk::create('127.0.0.1');
$tube = new TubeName('emails');
// 切换到目标 tube(默认生产到 "default")
$pheanstalk->useTube($tube);
// 普通投递:默认 priority=1024 / delay=0 / ttr=60
$pheanstalk->put(json_encode([
'to' => 'user@example.com',
'subject' => '订单已确认',
'body' => '感谢下单...',
], JSON_UNESCAPED_UNICODE));
// 高优先级(插队,priority=0 最紧急)
$pheanstalk->put(
data: json_encode(['to' => 'vip@example.com', 'subject' => 'VIP 工单'], JSON_UNESCAPED_UNICODE),
priority: 0,
);
// 延迟投递:30 秒后才变 ready;TTR 给 120 秒(发邮件可能慢)
$pheanstalk->put(
data: json_encode(['to' => 'delay@example.com', 'subject' => '定时提醒'], JSON_UNESCAPED_UNICODE),
delay: 30,
timeToRelease: 120,
);
echo "3 个任务已投递\n";
Worker(消费者,生产级骨架)
<?php
require 'vendor/autoload.php';
use Pheanstalk\Pheanstalk;
use Pheanstalk\Values\TubeName;
$pheanstalk = Pheanstalk::create('127.0.0.1');
$tube = new TubeName('emails');
// watch 必须单独一行,不能和 reserve 链式
$pheanstalk->watch($tube);
$pheanstalk->ignore(new TubeName('default')); // 不想要默认 tube
echo "Worker 启动,监听 [emails]...\n";
while (true) {
// reserveWithTimeout 避免永久阻塞,方便收到信号后退出
$job = $pheanstalk->reserveWithTimeout(60);
if ($job === null) {
continue; // 这 60 秒没来活儿
}
try {
$data = json_decode($job->getData(), true, flags: JSON_THROW_ON_ERROR);
sendMail($data);
$pheanstalk->delete($job);
echo "[OK] job #{$job->getId()} 处理完成\n";
} catch (\Throwable $e) {
// 区分瞬时错误 vs 永久错误
if (isTransient($e)) {
// 瞬时错误(下游服务抖动):放回去 5 秒后重试
$pheanstalk->release($job, delay: 5);
echo "[RETRY] job #{$job->getId()} 5 秒后重试\n";
} else {
// 永久错误(数据格式错):埋掉,留给人工
$pheanstalk->bury($job);
echo "[BURIED] job #{$job->getId()} 已埋:{$e->getMessage()}\n";
}
}
}
function sendMail(array $data): void { /* 你的业务 */ }
function isTransient(\Throwable $e): bool {
return $e instanceof \RuntimeException; // 按实际业务判断
}
这段 worker 骨架的关键是 catch 里的分流:瞬时错误 release(delay) 让它稍后重试,永久错误 bury 不再浪费循环。这是用 Beanstalkd 写队列的正确姿势,Redis 上你要自己实现一整套。
管理脚本:踢回被埋的 job
// 把被埋的 job 唤醒最多 100 个
$awakened = $pheanstalk->kick(100);
echo "唤醒了 {$awakened} 个 job\n";
// 看 tube 健康度
$stats = $pheanstalk->statsTube(new TubeName('emails'));
echo "ready={$stats->currentJobsReady} buried={$stats->currentJobsBuried}\n";
buried 堆积说明业务有 bug,拿这个指标做监控告警。
和 Redis 队列比,到底强在哪
先看数据。
Laravel 队列吞吐基准(jobs/sec,单 worker):
| 方案 | VPS | AWS c4.large |
|---|---|---|
| Beanstalkd | 1109 | 2600 |
| Redis | 872 | 1905 |
| MySQL 队列 | 190 | 452 |
Beanstalkd 比 Redis 快约 27%~37%。更值得看的是持久化场景——Beanstalkd 开着 binlog 都比 Redis 快。
开启持久化后的对比(n=1000,生产+消费总耗时):
| 方案 | 生产 | 消费 |
|---|---|---|
| Beanstalkd(binlog) | 1.0s | 1.4s |
| Redis(RDB) | 1.6s | 4.6s |
| Redis(AOF) | 2.0s | 7.7s |
| Beanstalkd(无 binlog) | 0.3s | 0.4s |
Beanstalkd 的 binlog 设计比 Redis 的 AOF 轻很多。开着持久化都比 Redis 快,这才是它真正能打的点。
功能层面的差异更直接:
| 能力 | Beanstalkd | Redis(List+BLPOP) |
|---|---|---|
| 延迟队列 | 原生 delay
|
ZSET + 轮询自己拼 |
| 优先级 | 原生 0~2³² | 多 List 手动调度 |
| TTR / 超时重派 | 原生 | 自己实现 |
| bury / kick | 原生 | 没有 |
| worker 崩溃后 job | 自动回队列 | 丢失 |
| 持久化 | binlog(可选) | RDB / AOF |
Redis 做队列不是不行,但你每加一个需求就要糊一层代码。糊到最后,就是个手搓的 Beanstalkd。
说点实话
Beanstalkd 不是银弹,它有明显的短板。
没有原生高可用。 Beanstalkd 是单点服务,官方没提供集群方案。生产环境要么用 supervisor/systemd 守护进程 + 业务侧分片(不同业务走不同实例),要么前端套负载均衡。想要 RabbitMQ 那种镜像队列?没有。这点必须接受。
管理工具弱。 自带的管理手段就是 telnet + stats 命令。想要 Web 界面得装第三方的 ptrofimov/beanstalk_console(纯 PHP)或 dyanakiev/laravel-beanstalkd-admin-ui(Laravel 项目内嵌)。和 RabbitMQ 自带的管理后台比差远了。
生态比 Redis 小。 Redis 你已经在用了,多一个场景不增加运维成本。Beanstalkd 是个新组件,要单独部署、监控、维护。
所以选型逻辑很清晰:
- 已有 Redis 且队列逻辑极简单(先进先出就够) → 直接用 Redis,别多引一个组件。
- 需要复杂路由、跨机房 HA、严格 ACK 语义 → RabbitMQ。
- 要一个专用、快、省心、binlog 够用的任务队列,能接受"单点 + 自己做 HA" → Beanstalkd。这是它的甜点区。
部署建议
生产环境用 Beanstalkd 记住几点:
开 binlog 但调好 fsync。-b <dir> 开启持久化,-f 100 表示断电最多丢 100ms 数据,-F(默认)是不 fsync 最快但断电丢全部。生产别用 -F。
调大 job body 上限。默认偏小(protocol 文档标注 64KB),发邮件带富文本会不够,用 -z 67108864 调到 64MB。
TTR 按真实业务上限设。宁可大不可小,频繁 DEADLINE_SOON 就是 TTR 太短的信号。长任务别傻把 TTR 设成 1 小时,改成正常值加周期 touch。
Worker 进程用 supervisor 拉起多个,别裸跑 PHP while 循环。进程崩了要能自动重启。
监控 current-jobs-buried 和 job-timeouts,这俩涨起来都是业务出问题的信号。
总结
Beanstalkd 解决的是一个很具体的问题:PHP 应用需要一个专门的任务队列服务,但又不想引入 RabbitMQ 的运维复杂度。它把 TTR、延迟、优先级、bury/kick 这些任务队列该有的东西原生做齐了,一个二进制跑起来,协议还能 telnet 调试。
如果你正在用 Redis List 手搓队列,而且已经糊了好几层补丁——是时候看看 Beanstalkd 了。
- 项目地址:https://github.com/beanstalkd/beanstalkd
- 协议文档:https://github.com/beanstalkd/beanstalkd/blob/master/doc/protocol.txt
- PHP 客户端:https://github.com/pheanstalk/pheanstalk
参考资料
- beanstalkd/beanstalkd - GitHub
- Beanstalkd Protocol
- Beanstalkd FAQ(TTR / bury / DEADLINE_SOON 权威解释)
- pheanstalk/pheanstalk - GitHub(PHP 客户端,v8.0.2)
- Laravel Queueing Benchmark - Beanstalkd vs Redis vs DB
- queue-performance-comparison(Rust 基准,Beanstalkd vs Redis)
原文标题: [beanstalkd]PHP 任务队列,我为什么放弃 Redis 选了它
原文地址: https://phpreturn.com/index/a6a3e7731b0151.html
原文平台: PHP武器库
版权声明: 本文由phpreturn.com(PHP武器库官网)原创和首发,所有权利归phpreturn(PHP武器库)所有,本站允许任何形式的转载/引用文章,但必须同时注明出处。