最近换个角度看 Artificial Analysis 的排行榜:不看模型本身,看它们跑在什么芯片上。每个模型背后站着一个芯片厂商,把对应关系排出来,比模型分数本身更有信息量。
数据来源为 Artificial Analysis 排行榜和各厂商公开信息(2026 年 4 月)。
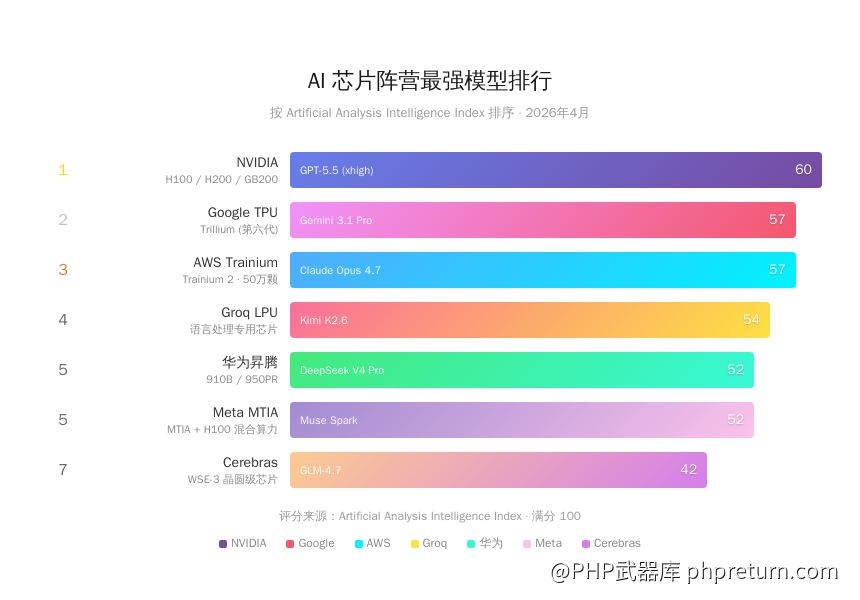
综合排名
| 排名 | 芯片阵营 | 代表芯片 | 最强模型 | Intelligence Index |
|---|---|---|---|---|
| 1 | NVIDIA | H100/B200 | GPT-5.5 (xhigh) | 60 |
| 2 | Google TPU | Trillium v6 | Gemini 3.1 Pro | 57 |
| 3 | AWS Trainium | Trainium 2 | Claude Opus 4.7 (max) | 57 |
| 4 | Groq LPU | LPU | Kimi K2.6 | 54 |
| 5 | 华为昇腾 | 昇腾950PR | DeepSeek V4 Pro (Max) | 52 |
| 5 | Meta MTIA | MTIA + H100 | Muse Spark | 52 |
| 7 | Cerebras | WSE-3 | GLM-4.7 (仅推理托管) | 42 |
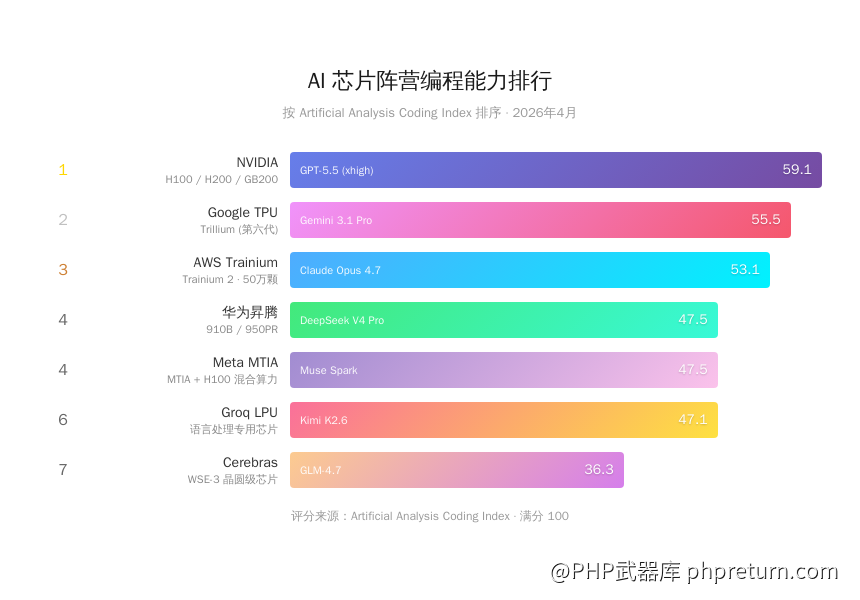
编程专项排行
Artificial Analysis 还有一套独立的编程评分体系(Coding Index)。按各芯片阵营的最强编程模型来排:
| 排名 | 芯片阵营 | 最强编程模型 | Coding Index |
|---|---|---|---|
| 1 | NVIDIA | GPT-5.5 (xhigh) | 59.1 |
| 2 | Google TPU | Gemini 3.1 Pro | 55.5 |
| 3 | AWS Trainium | Claude Opus 4.7 (max) | 53.1 |
| 4 | 华为昇腾 | DeepSeek V4 Pro (Max) | 47.5 |
| 4 | Meta MTIA | Muse Spark | 47.5 |
| 6 | Groq LPU | Kimi K2.6 | 47.1 |
| 7 | Cerebras | GLM-4.7 | 36.3 |
综合和编程两套评分不完全对应——综合智能高的不一定编程最强。以下按综合排名逐个说。
第一名:英伟达 + GPT-5.5
OpenAI 的 GPT-5.5 以 60 分排全球第一,运行在英伟达 H100 集群上,配合 TensorRT-LLM 实现推理优化。英伟达的壁垒在于生态体系——CUDA 软件栈、NVLink 互连、TensorRT 推理引擎,十多年积累,几乎所有顶级模型团队都建立在这个体系之上。
最新一代 GB200 Grace Blackwell Superchip 将两颗 B200 GPU 和一颗 Grace CPU 通过 900GB/s NVLink 连接,官方宣称推理性能比 H100 提升 30 倍。

第二名:Google TPU + Gemini 3.1 Pro
Gemini 3.1 Pro 评分 57,使用 Google 自研的第六代 Trillium TPU,完全不依赖英伟达 GPU。Gemini 的训练运行在由数万张 Trillium 芯片组成的集群上,通过自研光互连技术连接。单颗 Trillium 算力 512 TOPS,通过大规模集群部署和软件优化来弥补单芯片纸面性能差距。

第三名:AWS Trainium + Claude Opus 4.7
Claude Opus 4.7 评分 57,主力训练芯片为亚马逊自研的 Trainium 2。2026 年 AWS 完成 Project Rainier 项目,在美国多个数据中心部署超过 50 万颗 Trainium 2 芯片,专门用于 Anthropic 训练 Claude,年底计划增加到 100 万颗。亚马逊已承诺追加 250 亿美元投资,Anthropic 签订了 10 年内采购 5 吉瓦 Trainium 算力的合同。按芯片部署规模计算,这是目前全球最大的非英伟达 AI 训练集群。

第四名:Groq LPU + Kimi K2.6
Groq 开发的 LPU(Language Processing Unit)采用 TSA(张量流架构)设计,每个核心集成 230MB SRAM,计算全部在片上完成,绕开了传统 GPU 推理的内存带宽瓶颈。Moonshot AI 的 Kimi K2.6 运行在 Groq LPU 上,评分 54。Llama 70B 在 LPU 上的推理速度为 300 tokens/s。
2025 年 12 月,NVIDIA 以 200 亿美元完成对 Groq 的资产收购及核心团队吸纳。2026 年 GTC 大会上发布了 Groq 3 LPU,LPU 技术被整合进 NVIDIA AI 工厂架构。

第五名:华为昇腾 + DeepSeek V4 —— 这可能是最重要的一条
DeepSeek V4 Pro 评分 52,与 Meta 的 Muse Spark 并列第五。但分数不是这条的重点。
2026 年 4 月,DeepSeek V4 完成了从英伟达 CUDA 到华为昇腾 CANN 的全栈迁移。昇腾 910B 采用 7nm 工艺和达芬奇架构,最新的 950PR 也已量产。DeepSeek V4 系列已能在 910B 上完成单机及多机部署。
这件事的意义不在技术层面,而在产业格局。在芯片禁令持续收紧的背景下,全球第五的模型跑在全套国产芯片上——这意味着中国最强的开源模型已经脱离了对英伟达的依赖。从 CUDA 到 CANN,十几年的生态迁移,DeepSeek 只用了 16 个月。
前四名里的 Groq 被吞了,AWS 和 Google 靠的是自家体量,英伟达是十多年的生态壁垒。而 DeepSeek + 昇腾是唯一一个靠"被迫"走出来的路线,用被卡脖子的条件硬跑到了这个位置。
我不觉得 52 分就满意了,但它证明了一件事:国产算力链已经闭环。 以前说"国产替代"更像愿景和口号,现在它是一个能在榜单上和全球顶级玩家并列的事实。


除了华为,国内其他芯片厂商也在快速跟进。寒武纪在 DeepSeek-V4 发布当天完成了 Day 0 适配,基于自研 vLLM-MLU 推理引擎,同时支持 V4-Pro 和 V4-Flash 两个版本,适配代码已开源——这已经不是第一次了,之前 V3.2 发布时也是当天同步。海光 DCU 走的是 GPGPU 架构、兼容类 CUDA 环境的路线,宣称可实现 DeepSeek 的"零等待"部署。加上昆仑芯、天数智芯等也在做适配,DeepSeek-V4 目前在国产芯片上的可用选项已经不限于一家。
这意味着国产算力正在从"能不能跑"过渡到"你选哪家"的阶段。华为昇腾拿了最高分,但背后是一条正在成型的供应链。
第五名(并列):Meta MTIA + Muse Spark
Muse Spark 评分 52,由 Meta Superintelligence Labs 开发,是 Meta 首个闭源模型。该模型直接集成到 WhatsApp、Instagram、Facebook 等 Meta 旗下应用中,面向超过 30 亿月活用户,不提供 API 和开源权重。
硬件方面,Meta 目前拥有 35 万张 H100 GPU 的大规模集群,同时自研 MTIA 芯片,与 Broadcom 签署了多代芯片联合开发协议,与 AMD 签署了 6GW 芯片供应协议。Muse Spark 在此混合算力体系下训练。

第七名:Cerebras WSE-3 + GLM-4.7
Cerebras 采用晶圆级芯片设计,将整块晶圆作为单个芯片。第三代 WSE-3 拥有 4 万亿晶体管、90 万个 AI 核心,片上内存带宽 21 PB/s,约为 H100 的 7000 倍。
Cerebras 本身不训练模型,只提供推理托管服务。平台上推理速度最高的模型为 Llama 3.1 8B(2337 tokens/s),Llama 4 Maverick 在其上创下 400B 参数模型的推理纪录(969 tokens/s)。平台上评分最高的模型为智谱 Z.ai 的 GLM-4.7,Intelligence Index 为 42。

整理完这个榜单,我的两个判断
-
DeepSeek + 昇腾的组合是中国算力的分水岭。 以前说"国产替代"总觉得差一口气,但头部模型已经能在国产芯片上跑出全球第五的成绩,这是从 0 到 1 的变化。
-
Cerebras 这种"极致专用"路线,天花板看得见。 把所有晶体管堆在一个晶圆上追求绝对速度,在特定场景确实做到了英伟达做不到的事。但只能推理不能训练、只能托管别人模型——这条路能走多远,取决于它能不能找到自己的"引擎"。
这个榜单我会持续跟踪。毕竟芯片格局的变化,最终会决定我们能用到什么样的模型。
参考资料
- Artificial Analysis LLM Leaderboard
- Artificial Analysis Coding Index
- 英伟达官方确认 GPT-5 使用 H100/H200 训练
- GPT-5.5 + Codex 落地 NVIDIA 基础设施
- Gemini 3 使用 TPU 训练,零英伟达依赖
- Google Trillium TPU 详解
- AWS Project Rainier: 50万颗 Trainium 2 支持 Claude
- NVIDIA 收购 Groq 资产 $200 亿美元
- NVIDIA Groq 3 LPU 发布,GTC 2026
- Kimi K2.6 编程基准详解
- DeepSeek V4 全面适配华为昇腾 950PR
- DeepSeek V4 昇腾 910B 部署指南
- 昇腾社区 DeepSeek 专区
- Cerebras WSE-3 推理性能:Llama 405B 达 969 tok/s
- Cerebras 模型列表(Artificial Analysis)
- Groq LPU vs 英伟达 GPU 全维度解析
- 国产 AI 算力突围:昇腾承接万亿市场
- Meta AI 基础设施:35万 H100 GPU
- Meta Muse Spark 发布
- Meta + Broadcom 联合开发 MTIA 芯片
- SWE-bench Verified 排行榜
原文标题: AI 推理芯片阵营排行:谁在孵化最强模型
原文地址: https://phpreturn.com/index/a69f1c08b2ab9a.html
原文平台: PHP武器库
版权声明: 本文由phpreturn.com(PHP武器库官网)原创和首发,所有权利归phpreturn(PHP武器库)所有,本站允许任何形式的转载/引用文章,但必须同时注明出处。