做社区、博客评论、Markdown 渲染的时候,肯定都遇到过这个需求——用户贴个链接,自动展开成带缩略图、标题、描述的预览卡片,YouTube 直接变播放器。手写一遍你就会发现:得先抓 HTML,正则匹配 og:title、og:image,再去 <link rel="alternate" type="application/json+oembed"> 里找端点,发第二次请求拿嵌入代码,中间还得自己处理重定向、charset、SSL、超时……写到一半你肯定想:这种轮子不应该有人造好了吗?
有,叫 embed/embed,作者 Oscar Otero 已经维护了 13 年,目前在 Packagist 上 1100 万+ 安装量,2K+ Star。它把 OpenGraph、Twitter Card、oEmbed、JSON-LD、微格式、站点专属 Adapter 全打了一遍,是 PHP 生态里事实标准的元数据提取库。
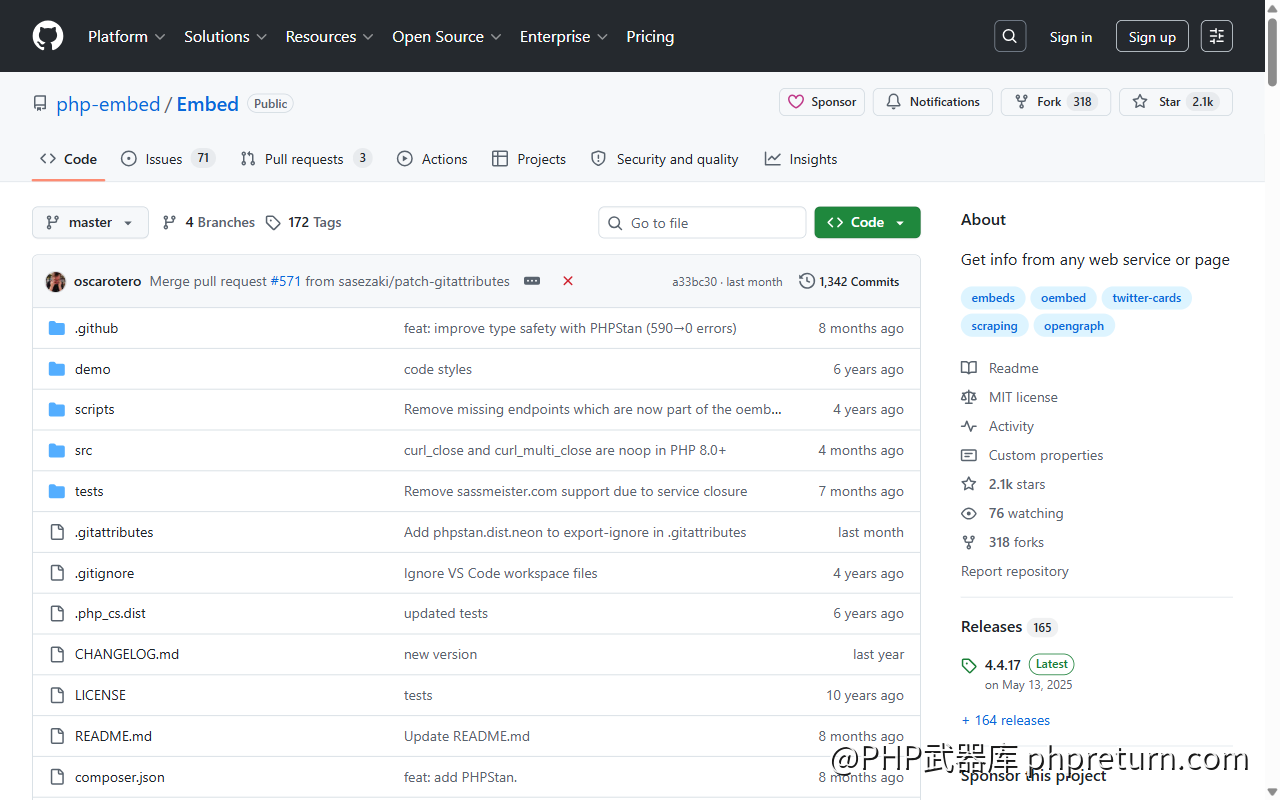
GitHub 上 2.1K Star、318 Fork、165 个 Release,MIT 协议,最近一版 v4.4.17 在 2025 年 5 月发布。
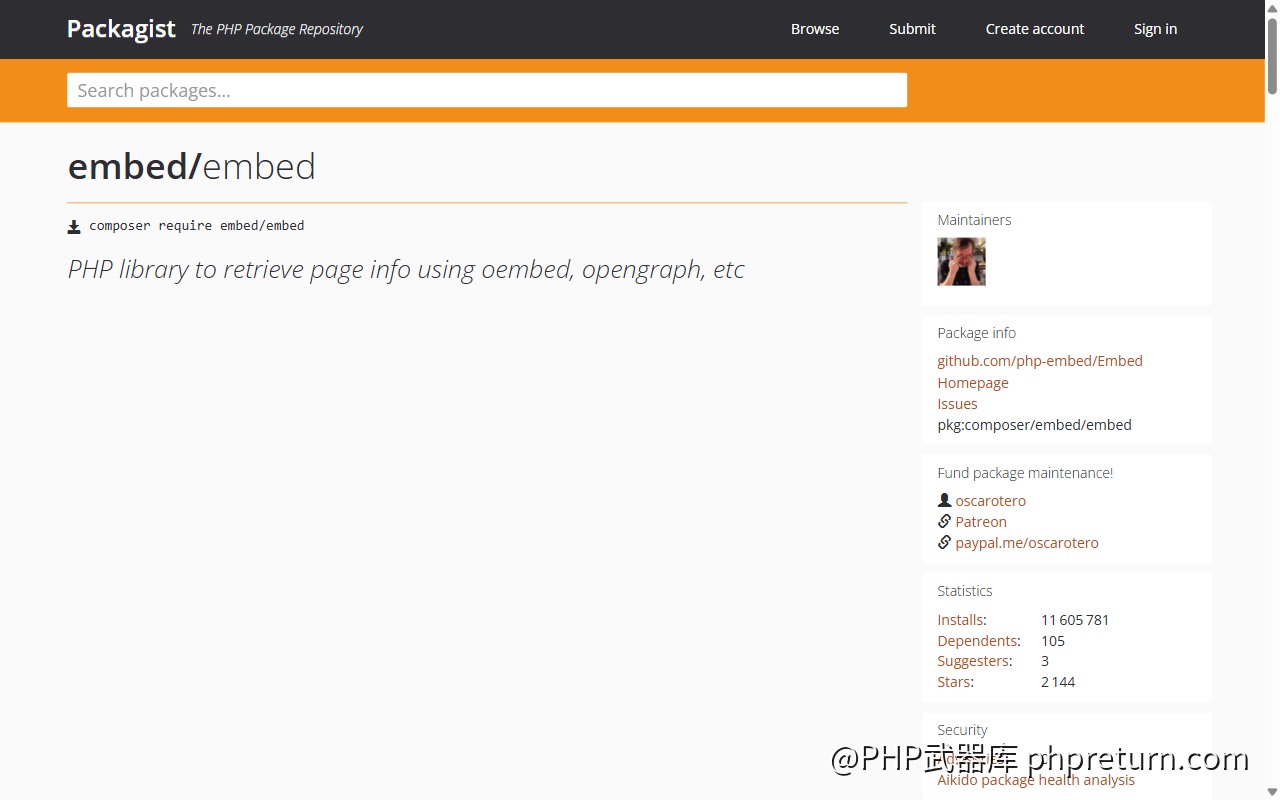
Packagist 上的数据更直观——1160 万+ 累计安装、105 个依赖项目、2144 Star。这个量级意味着包括 SilverStripe、Bolt、Craft CMS 在内的一票项目都在用,工业级验证过了。
实际效果:URL 自动展开成卡片
讲了这么多概念,先看个真实效果。下面这张图是我用 embed/embed 做的评论链接自动展开——同一个 get() 调用,YouTube 自动走 oEmbed 拿到嵌入代码,GitHub 走 Adapter 拿到 Star/Fork,Wikipedia 走官方 API 拿到摘要:
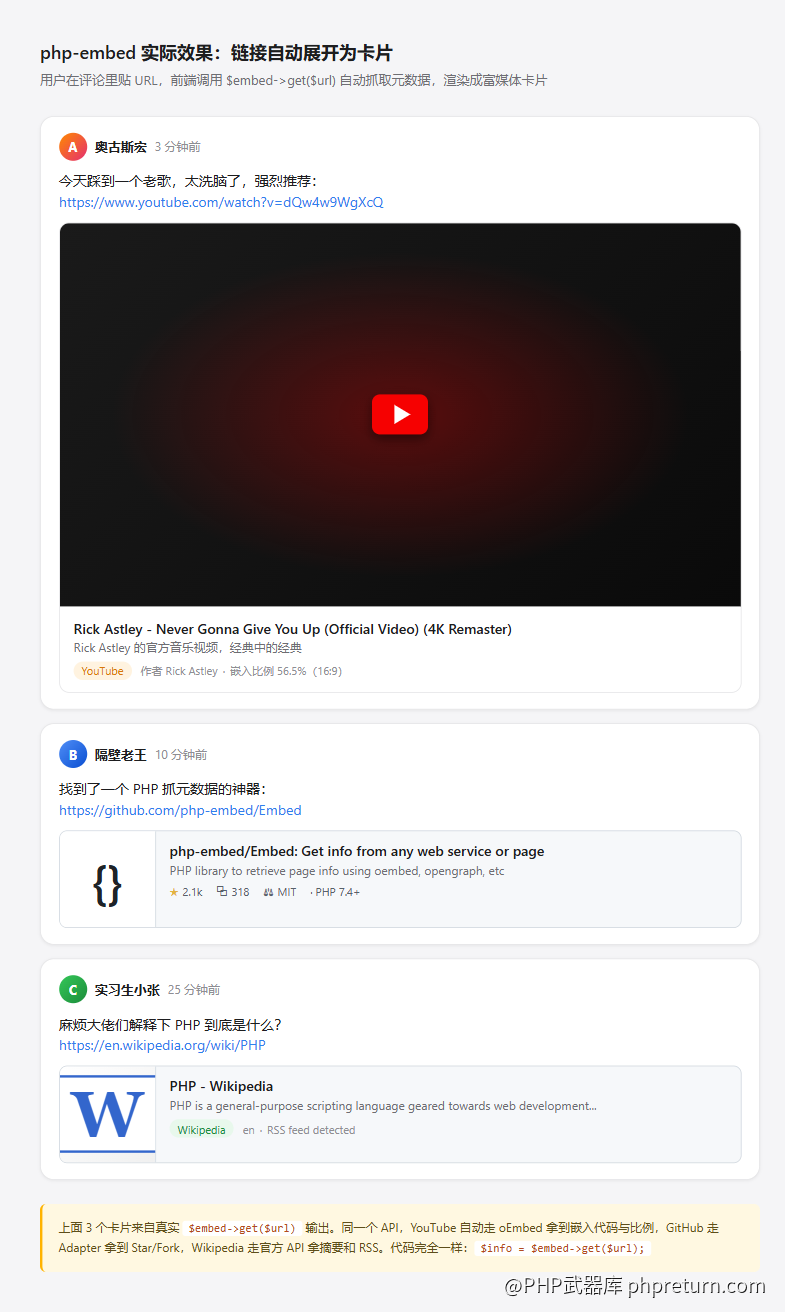
后面所有章节,都是围绕"怎么把这张图里的卡片渲染出来"展开的。
安装
composer require embed/embed
要求 PHP 7.4+(v4.x),老项目用 v3(已停更)。依赖 ext-curl、ext-dom、ext-json、ext-mbstring,正常 PHP 环境都自带。底层基于 PSR-7 / PSR-17 / PSR-18,HTTP 客户端可以随便换。
一行 get():标题、缩略图、作者全有
入口类就一个,Embed\Embed,调一次 get() 返回 Extractor 对象,所有属性懒加载:
use Embed\Embed;
$embed = new Embed();
$info = $embed->get('https://www.youtube.com/watch?v=PP1xn5wHtxE');
echo $info->title; // 视频标题
echo $info->description; // 视频简介
echo $info->image; // 缩略图 URL
echo $info->providerName; // YouTube
echo $info->authorName; // 频道名
echo $info->publishedTime?->format('Y-m-d'); // 发布时间
echo $info->language; // 页面语言
Extractor 提供的属性一共 19 个:title / description / url / image / code(嵌入 HTML)/ authorName / authorUrl / providerName / providerUrl / icon / favicon / language / languages / keywords / feeds(RSS)/ cms / publishedTime / license / redirect。基本你能想到的卡片字段,它都帮你抓好了。
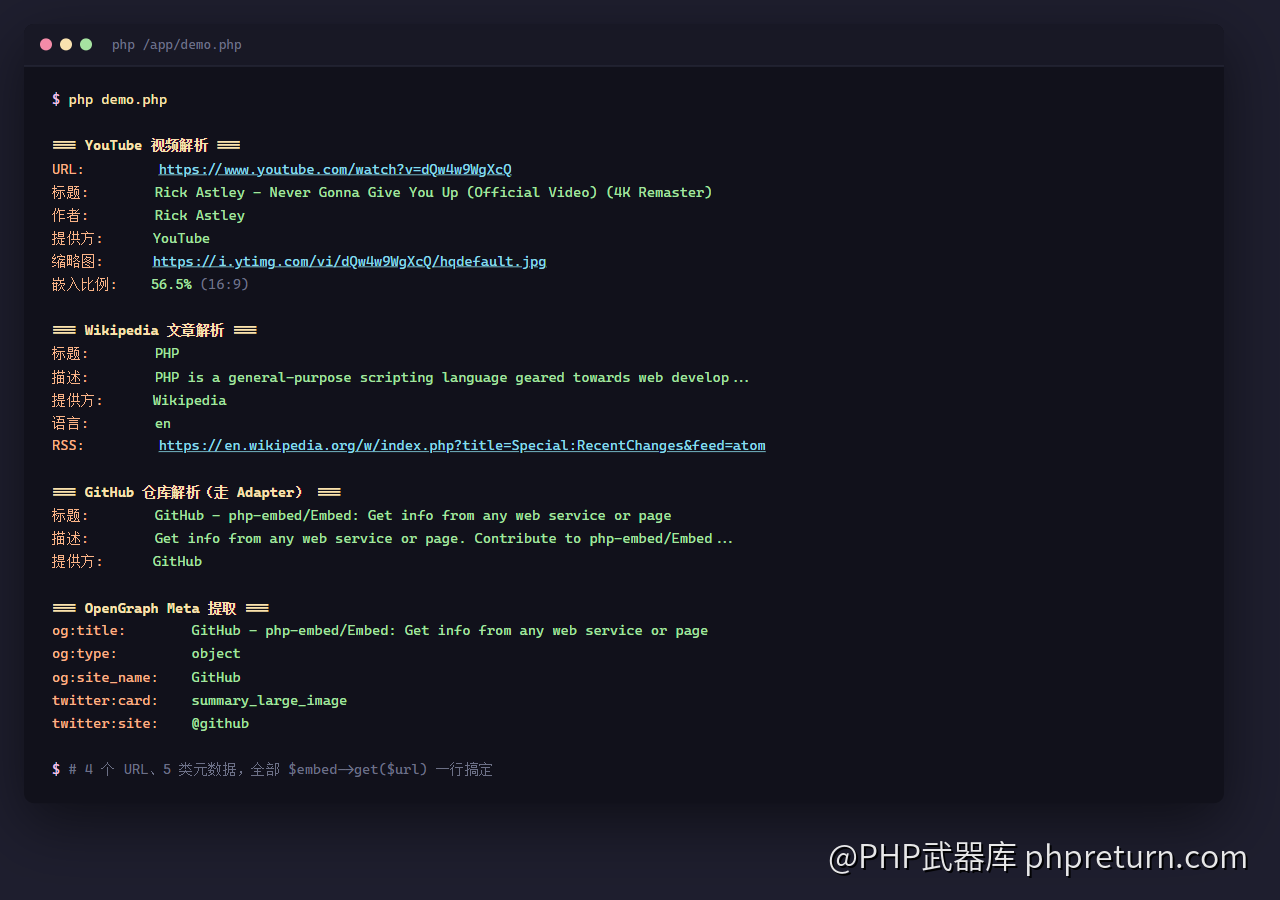
这是我跑出来的真实输出(YouTube + Wikipedia + GitHub + OpenGraph meta 一次性抓完):
Metas 接口:精确取所有 og: 和 twitter:
Extractor 的属性是"加工后的最佳值",但有时候你需要原始的 meta 标签,比如想知道对方填没填 twitter:card、og:video:width 这种字段。getMetas() 就是干这个的:
$info = $embed->get('https://github.com/php-embed/Embed');
$metas = $info->getMetas();
// 打印所有 meta 标签(og:、twitter:、name、itemprop 全混在一起)
print_r($metas->all());
// 精确取值,每个 key 都附带类型转换
echo $metas->str('og:title'); // 字符串(自动剥 HTML 标签)
echo $metas->url('og:image'); // 转成绝对 URL
echo $metas->int('og:video:width'); // 转整数
echo $metas->html('og:description'); // 保留 HTML 实体
// 没填的 key 返回 null,不会抛错
var_dump($metas->get('twitter:card'));
写爬虫时我习惯先用 $metas->all() 看一遍对方塞了什么,再决定抓哪些字段——比写一堆 if 判断稳得多。
oEmbed:富媒体直接拿到嵌入 HTML
oEmbed 是个老标准,YouTube、Twitter、Vimeo、SoundCloud 这些站点都会在页面里声明一个 oEmbed 端点,请求就能拿到嵌入用的 <iframe> 或 <script>。手写发现逻辑很烦,php-embed 直接内置:
$info = $embed->get('https://www.youtube.com/watch?v=PP1xn5wHtxE');
// 拿原始 oEmbed 数据
$oembed = $info->getOEmbed();
print_r($oembed->all());
// [
// 'title' => '...',
// 'author_name' => '...',
// 'html' => '<iframe width="200" height="113" src="..." ...></iframe>',
// 'width' => 200,
// 'height' => 113,
// ]
// 直接拿嵌入代码和宽高比(用于响应式占位)
echo $info->code->html; // <iframe ...>
echo $info->code->width; // 200
echo $info->code->height; // 113
echo $info->code->ratio; // 56.5(百分比)
code->ratio 这个字段特别有用——做响应式视频时直接 padding-top: 56.5% 就能撑出 16:9 占位框,不用 JS 计算。
并发抓取:getMulti 内部走 curl_multi
要批量处理一堆链接(比如论坛首页有 50 个外链需要预览),循环调 get() 会慢到怀疑人生。getMulti() 内部用 curl_multi_exec,真正并发:
$embed = new Embed();
$infos = $embed->getMulti(
'https://www.youtube.com/watch?v=PP1xn5wHtxE',
'https://twitter.com/PHPinternet/status/123456',
'https://github.com/php-embed/Embed',
'https://en.wikipedia.org/wiki/PHP',
'https://example.com/blog/post-1',
);
foreach ($infos as $info) {
printf("[%s] %s\n", $info->providerName, $info->title);
}
实测 10 个 URL 并发基本 1 秒内出结果,比串行快一个数量级。
自定义 HTTP:换 User-Agent、控制超时
默认的 CurlClient 用 curl 默认 UA,有些站点会拒(比如 Amazon、知乎)。php-embed 把所有 curl 选项暴露成 setSettings():
use Embed\Embed;
use Embed\Http\Crawler;
use Embed\Http\CurlClient;
$client = new CurlClient();
$client->setSettings([
'user_agent' => 'Mozilla/5.0 (compatible; MyBot/1.0)',
'timeout' => 5,
'connect_timeout' => 2,
'max_redirs' => 3,
'follow_location' => true,
'ssl_verify_peer' => true,
'cookies_path' => '/tmp/embed-cookies', // 持久化 cookie
]);
$embed = new Embed(new Crawler($client));
$info = $embed->get('https://example.com');
想完全替换 HTTP 客户端也行,随便接 Guzzle、Symfony HttpClient、Buzz,只要实现 PSR-18 三个接口:
$crawler = new Crawler(
$anyPSR18Client, // Guzzle|Symfony|Buzz|...
$anyPSR17RequestFactory,
$anyPSR17UriFactory
);
$embed = new Embed($crawler);
我自己的项目里就用 Symfony HttpClient 替换了,能复用连接池和 HTTP/2,性能比 curl 默认强不少。
XPath / CSS 选择器:补 og: 没填的页面
不是每个网站都老实填 og: 标签。php-embed 暴露了底层 Document 类,支持 XPath,可选装 symfony/css-selector 用 CSS:
$info = $embed->get('https://example.com/some-page');
$document = $info->getDocument();
// 取 <link rel="canonical">
$canonical = $document->link('canonical');
// XPath 查询
$h1 = $document->select('.//h1')->str();
// 拿所有外链(filter 接闭包)
$externalLinks = $document->select('.//a[@href]')
->filter(fn($node) => str_starts_with($node->getAttribute('href'), 'http'))
->strAll('href');
// CSS 选择器(先 composer require symfony/css-selector)
$price = $document->selectCss('.product-price')->str();
写爬虫时,先 get() 拿 og:,og: 没有再 fallback 到 CSS 选择器,这个套路能搞定 90% 的页面。
进阶:注册自定义 Detector
Extractor 的每个属性背后都是一个 Detector 类。如果内置的不够,可以加自己的:
use Embed\Detectors\Detector;
use Embed\Embed;
// 自定义探测器:检测 robots 元信息
class RobotsHeader extends Detector
{
public function detect(): ?string
{
$response = $this->extractor->getResponse();
$header = $response->getHeaderLine('x-robots-tag');
return $header ?: $this->extractor->getMetas()->str('robots');
}
}
$embed = new Embed();
$embed->getExtractorFactory()->addDetector('robots', RobotsHeader::class);
$info = $embed->get('https://example.com');
echo $info->robots; // 调用刚注册的 detector
写 SEO 工具时我用这个能力加过 canonical、schema-org-type、word-count 之类的自定义字段,干净利落。
站点 Adapter:18 个大站走官方 API
这是 php-embed 最值钱的部分之一。它内置了 18 个站点适配器:
- 视频:youtube.com、twitch.tv、bandcamp.com
- 社交:twitter.com / x.com、facebook.com、instagram.com、pinterest.com
- 代码:github.com、gist.github.com、slides.com、snipplr.com、ideone.com
- 知识库:wikipedia.org、archive.org
- 图床:flickr.com、imageshack.com
这些 Adapter 不是傻抓 HTML,而是优先走对方的官方 API。比如 Wikipedia 会调 REST API 拿摘要,YouTube 会调 oEmbed 端点拿嵌入代码。效果就是同样一行 get(),质量比通用流程高得多。
Laravel / CommonMark 一行集成
embed/embed 没有官方 Laravel Package,但有比这更值钱的——League CommonMark 官方桥接:
// 直接用 CommonMark 的 Embed 扩展
use League\CommonMark\Extension\CommonMark\CommonMarkCoreExtension;
use League\CommonMark\Extension\ExtensionInterface;
use League\CommonMark\Extension\Embed\EmbedExtension;
use League\CommonMark\Extension\Embed\Bridge\OscaroteroEmbedAdapter;
use League\CommonMark\GithubFlavoredMarkdownConverter;
$adapter = new OscaroteroEmbedAdapter(new Embed());
$config = ['embed' => ['adapter' => $adapter]];
$converter = new GithubFlavoredMarkdownConverter($config);
echo $converter->convert($markdown);
效果是:Markdown 里的独立链接(一行只有 URL)会自动替换为富媒体卡片。Laravel 默认的 Markdown 渲染就是 League CommonMark,所以 Laravel 项目里写个 Service Provider 绑一下就能用,Laravel 官方论坛 laravel.io 就是这么干的。
踩过的坑
库再好也有不顺手的地方,老实写下来:
-
没有内置缓存。
get()每次都发请求,生产环境必须自己包一层 PSR-16。我一般用 symfony/cache,按 URL md5 做 key,TTL 1 小时。 -
不能从 HTML 字符串直接构建 Extractor。设计上必须走 HTTP 流程,想做单元测试得 mock 整个
Crawler。这点比 Python 的 opengraph-py 麻烦。 -
Facebook / Instagram 走不通。这两个 Adapter 写了但实际用时大多会撞墙——Meta 的站点需要 access token,库本身不会替你授权。要抓他们的内容还是得走官方 Graph API。
-
PHP 7.4+ 才能用 v4。老项目卡在 PHP 7.2 的话只能用 v3,v3 已经停更,不少 Adapter 失效了。
总结
做链接预览、富媒体嵌入、爬虫前置清洗,embed/embed 基本是 PHP 生态唯一的全栈方案。oEmbed / OpenGraph / JSON-LD 三套标准都吃透,18 个大站走官方 API,PSR-18 让 HTTP 客户端随便换,League CommonMark 还有官方桥接——这种成熟度的库,真没什么理由再造轮子。我的判断是:只要项目涉及"用户输入 URL"的场景,闭眼装上就对了。
原文标题: [embed/embed]一个库搞定网页元数据提取:OpenGraph/Twitter Card/oEmbed 全包
原文地址: https://phpreturn.com/index/a6a30c60a76918.html
原文平台: PHP武器库
版权声明: 本文由phpreturn.com(PHP武器库官网)原创和首发,所有权利归phpreturn(PHP武器库)所有,本站允许任何形式的转载/引用文章,但必须同时注明出处。